Источник: Claude Opus 4.6 vs Claude Sonnet 4.6: кто лучше? (Habr, 2026)
Индустрия ИИ не сбавляет обороты: только за последний месяц мы увидели релизы Gemini 3.1 Pro и ChatGPT 5.3 Codex. Но главными героями этой весны для меня стали обновления от Anthropic — Claude Sonnet 4.6 и Claude Opus 4.6.
Как AI Advocate и создатель PRGate (платформы для автоматизированного policy-aware ревью кода, GitHub), я ежедневно тестирую новые LLM. Для меня крайне важно понимать, какая модель лучше справляется с глубоким анализом контекста (что критично для код-ревью), а какая — идеальна для потоковой рутины и генерации контента.
В этой статье мы разберем практическое сравнение Claude Opus 4.6 и Sonnet 4.6 на рутинных задачах, без скучных бенчмарков.

Позиционирование: Opus 4.6 или Sonnet 4.6?
Прежде чем переходить к тестам, давайте зафиксируем, для чего Anthropic создавали эти две модели.
Claude Opus 4.6: Флагман для глубокой аналитики
Это тяжелая, дорогая, но невероятно умная модель. Ее главное преимущество — способность удерживать гигантский контекст и выполнять сложные многоходовые размышления. В рамках PRGate мы задействуем такие мощности для глубокого контекстного анализа pull request'ов, проверки соблюдения корпоративных политик и архитектурного ревью кода. Opus — это не про скорость, а про ультимативное качество проверки.
Claude Sonnet 4.6: Сбалансированная рабочая лошадка
Sonnet 4.6 занимает золотую середину: он быстрее и дешевле, но при этом обладает серьезной экспертизой. Это идеальный выбор для потоковой генерации контента, базового кодинга и ежедневной рутины. Большинство агентов в автоматизированных пайплайнах работают именно на таких "средних" моделях.
Для любителей цифр — официальные бенчмарки (и почему в тексте всплывает Gemini):
| Бенчмарк | Сфера | Gemini 3.1 Pro | Claude 4.6 Opus | Claude 4.6 Sonnet | GPT-5.2 Pro |
|---|---|---|---|---|---|
| MMLU | Базовые знания | 91.3% | 89.2% | 87.5% | 88.0% |
| GPQA | Сложная логика | 62.4% | 61.3% | 55.7% | 53.6% |
| MATH | Математика | 82.3% | 80.5% | 75.8% | 73.5% |
| HumanEval | Кодинг | 90.6% | 89.1% | 86.4% | 87.1% |
| MGSM | Multilingual Math | 92.5% | 91.0% | 88.3% | 89.5% |
Интересный факт: Хотя в данном тесте мы сталкиваем лбами две модели от Anthropic, оригинальный автор в конце статьи делает внезапный вывод в пользу Gemini. Если посмотреть на таблицу выше, становится понятно почему: Gemini 3.1 Pro обходит конкурентов в большинстве синтетических тестов. Тем интереснее проверить, как модели Claude покажут себя на реальных рутинных задачах.
Тестирование на реальных задачах: кто лучше?
Оригинальное сравнение на Хабре включало 4 этапа. Я проанализировал их результаты через призму потребностей CTO и специалиста по контенту.
1. Генерация контента и сторителлинг
Задача: Написать юмористический рассказ в сеттинге фэнтези с сохранением логики и тонкой иронией.
🥇 Claude Opus 4.6 (3 из 3 баллов)
Opus выдал отличный, связный текст с уместным юмором. Читается легко, структура выдержана. Для задач копирайтинга, сторителлинга и создания маркетингового контента флагман Anthropic остается вне конкуренции.

🔴 Claude Sonnet 4.6 (1 из 3 баллов)
Младшая модель откровенно разочаровала. Текст получился сухим, "пластиковым" и без обещанной комедии. Использовать Sonnet для сложных креативных задач без цепочки агентов-редакторов пока не стоит.

2. Саммеризация и выжимка (Анализ технической документации)
Задача: Сделать выжимку из лекционного материала, сохранив все ключевые смыслы и детали.
⚖️ Ничья (по 2 балла)
В моей DevOps-практике часто нужно суммаризировать логи инцидентов или документацию. В этом тесте Opus 4.6 сделал хорошую текстовую выжимку, но потерял почти все важные формулы.

Sonnet 4.6 справился с формулами чуть лучше, но обе модели показали, что при сжатии технического контента за ними нужен жесткий контроль (промптинг на обязательное сохранение артефактов).
3. Математика и логика
Задача: Решить 4 математические задачи разного уровня сложности.
⚖️ Ничья (по 3.5 балла)
Обе модели справились отлично, решив почти все без ошибок, но обе немного споткнулись в финальном оформлении ответа в последнем задании (не заменили переменную в финале).


4. Программирование (Взгляд CTO)
Задача: Написать на Python десктопный инженерный калькулятор с GUI и встроенной игрой "Змейка" (Zero-shot промпт).
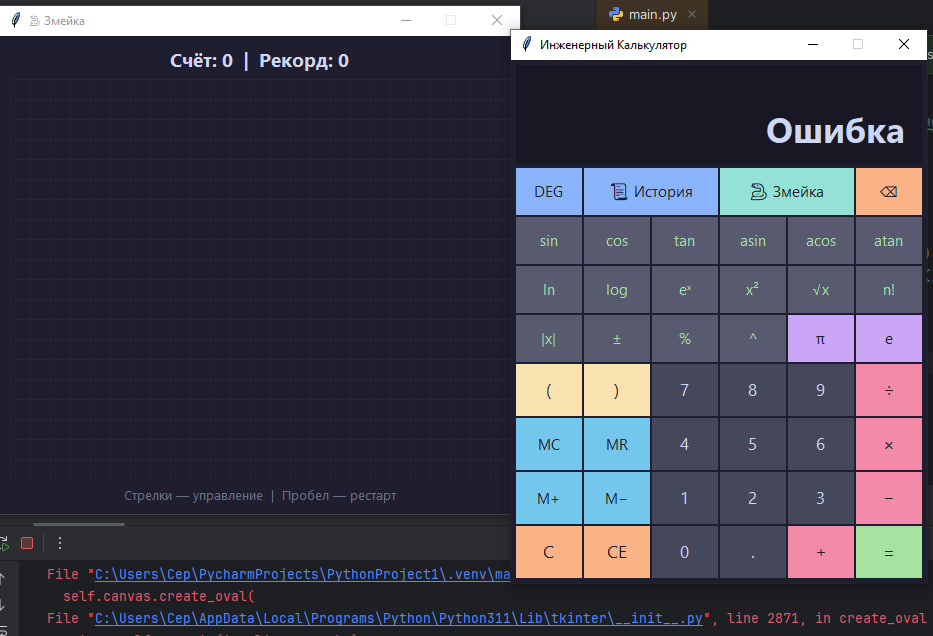
🔴 Claude Opus 4.6 (0 баллов)
Ожидаемо, что флагман должен был разорвать этот тест. Но вышло наоборот: Opus выдал красивый дизайн калькулятора, в котором не работает ничего. Змейка просто сыплет ошибками при запуске.
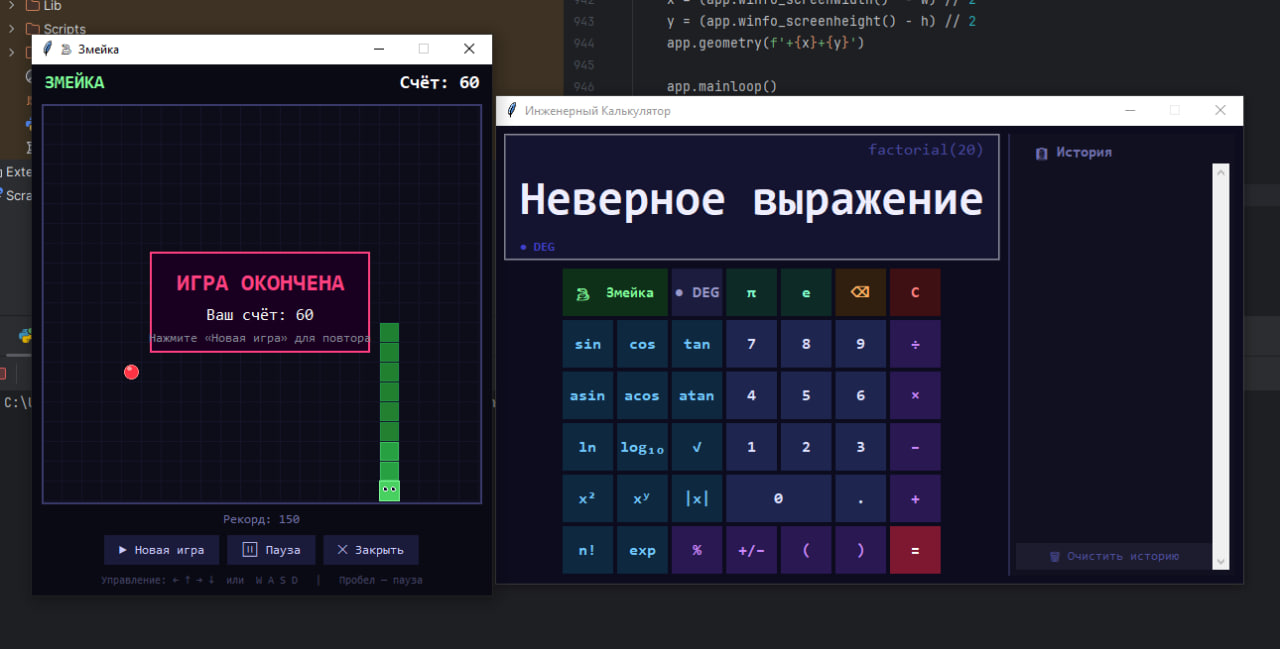
🥇 Claude Sonnet 4.6 (1 балл)
Младшая модель удивила. Змейка работает отлично, базовые операции калькулятора — тоже (хоть сложные функции и отвалились).
Инсайт для CTO: Это отличная иллюстрация того, что в 2026 году писать сложный софт одним промптом — плохая идея. Качественная разработка с ИИ строится на Agentic Workflows, где модель итеративно пишет код, запускает тесты и сама себя исправляет (например, в Cursor).
Итоги: Какую модель выбрать?
| Критерий | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|
| Генерация контента | 3 | 1 |
| Выжимка данных | 2 | 2 |
| Математика | 3.5 | 3.5 |
| Написание кода | 0 | 1 |
| Итоговый балл | 8,5 | 7,5 |
Вердикт:
- Выбирайте Claude Opus 4.6, если ваша задача — глубокий анализ кода, контекстное ревью сложных Pull Requests или разработка сложных стратегий. Для PRGate это базовая модель на этапе проверки архитектурных политик.
- Выбирайте Claude Sonnet 4.6, если вам нужно обрабатывать потоки данных, писать простые скрипты или вы используете итеративный подход (например, в IDE).
🤖 Бонус: Промпт для тестирования LLM
Как и обещал, делюсь системным промптом, который поможет вам выбрать лучшую нейросеть под задачи вашего бизнеса. Используйте его в режиме диалога, чтобы LLM выступила в роли независимого арбитра:
Ты — Senior AI Architect и Lead Prompt Engineer. Моя задача — выбрать лучшую LLM для интеграции в мой продукт (ОПИШИ СВОЙ ПРОДУКТ, например: платформа PRGate для автоматизированного ревью кода).
Я предоставлю тебе 2 варианта ответов от разных моделей (например, Claude 4.6 Opus и Sonnet) на один и тот же тестовый запрос. Твоя задача:
1. Провести слепое ревью каждого ответа по критериям: качество текста/кода, удержание контекста, следование формату, наличие галлюцинаций.
2. Оценить ответы по 10-балльной шкале.
3. Указать конкретные плюсы и минусы каждого варианта в контексте бизнес-ценности для моего продукта.
4. Выдать итоговую рекомендацию: какую модель выгоднее использовать с точки зрения соотношения "цена/качество/скорость".
Жди моих вводных с тестовыми ответами!
Дисклеймер / Disclaimer: material is published for informational and research purposes. Полный отказ от ответственности / Full disclaimer.